Introduzione
Abbiamo introdotto un importante livello di caching per risparmiare tempo, migliorare le performance, ottimizzare i costi e rendere possibile l’utilizzo efficiente del sistema in modalità serverless.
Un intervento apparentemente semplice, ma che ha cambiato radicalmente il modo in cui una delle nostre architetture si comporta sotto carico.
Il contesto
Uno dei nostri clienti — una realtà del settore retail con un ecosistema digitale basato interamente su AWS Lambda, API Gateway e NestJS — stava riscontrando un problema ricorrente:
l’applicazione era scalabile in teoria, ma in pratica presentava latenze elevate e costi in crescita, nonostante la struttura serverless.
Ogni richiesta, anche per dati identici, doveva riavviare l’intera catena:
Lambda → query verso Aurora Serverless → serializzazione → risposta.
Un modello elegante ma poco efficiente quando le stesse informazioni venivano richieste migliaia di volte al giorno.
L’approccio
Il primo passo è stato misurare: tramite AWS X-Ray e CloudWatch Insights abbiamo tracciato dove si disperdevano i millisecondi.
La risposta era chiara: troppi round trip verso il database, nessuna persistenza di dati temporanei.
In un ambiente serverless, dove ogni funzione vive pochi istanti, la memoria volatile non è una soluzione.
Serviva un layer esterno, veloce, economico e scalabile.
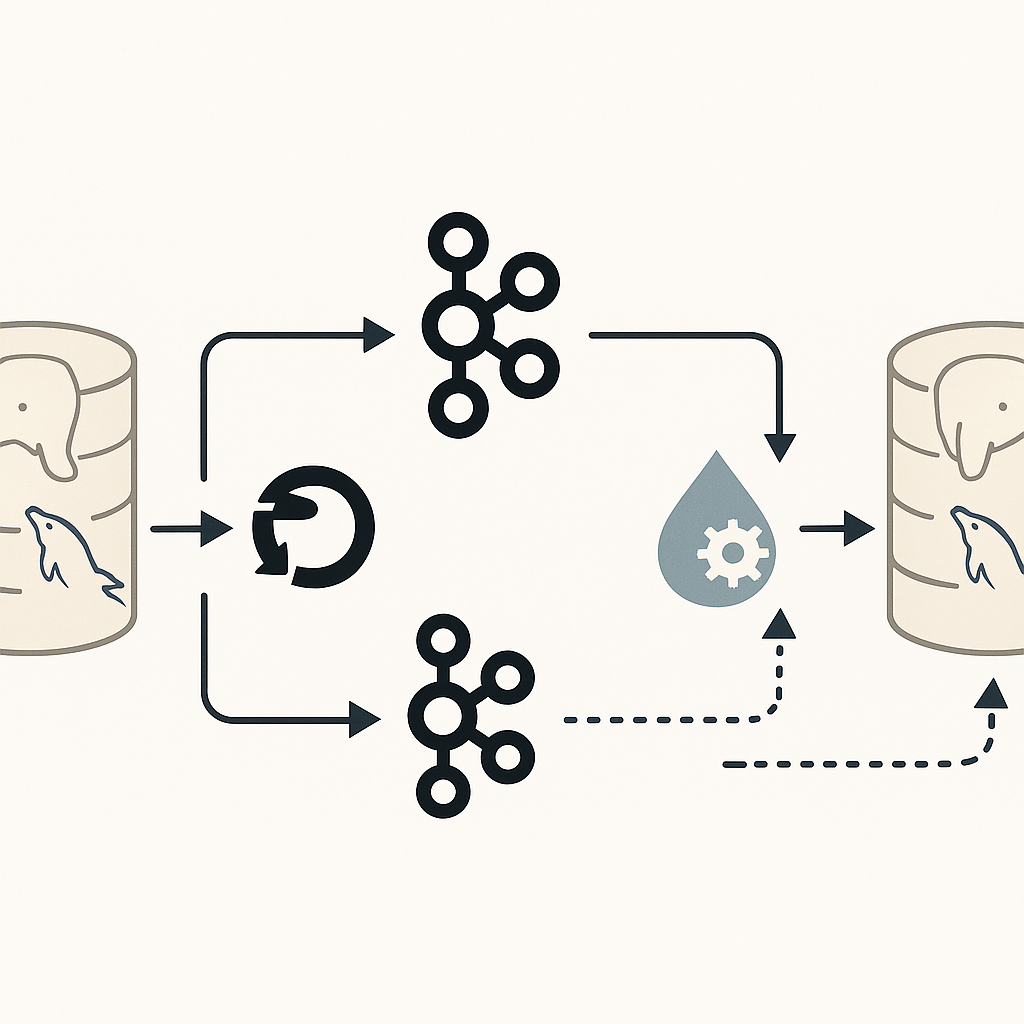
Abbiamo quindi introdotto un livello di caching distribuito su DynamoDB, progettato come archivio chiave-valore con TTL automatico (time-to-live).
Il sistema conserva per pochi minuti i risultati delle chiamate più costose, permettendo alle Lambda successive di rispondere in millisecondi, senza interrogare Aurora.
L’architettura finale
Il flusso delle richieste è oggi completamente ridisegnato:
- API Gateway riceve la richiesta.
- Lambda (NestJS) controlla il layer di caching su DynamoDB.
- Se il dato è disponibile, risponde immediatamente.
- In caso contrario, interroga Aurora Serverless, aggiorna la cache e restituisce la risposta.
Il tutto orchestrato in modo trasparente per l’utente finale e completamente automatizzato tramite GitHub Actions e AWS CDK, per garantire versioning e deployment consistenti.
I risultati
L’impatto è stato immediato:
- Latenza media ridotta di oltre l’85%.
- Query al database ridotte del 90%.
- Costi AWS complessivi diminuiti di circa il 40%.
- Nessun impatto sulla scalabilità, anzi: la cache distribuita ha reso le Lambda ancora più stateless e performanti.
In pratica, l’applicazione ha smesso di “ricominciare da zero” a ogni chiamata.
E il sistema serverless, da elegante sulla carta, è diventato finalmente efficiente nella realtà.
Una lezione importante
Questo caso ci ha ricordato una verità che chi lavora nel cloud spesso sottovaluta:
Serverless non significa rinunciare all’ottimizzazione.
Significa ottimizzare in modo diverso.
La cache non è un lusso o un add-on, ma un pilastro di qualsiasi architettura realmente scalabile.
Nel mondo serverless, dove ogni funzione è effimera, il caching è ciò che dà continuità.
Stack coinvolto
- AWS Lambda (Node.js 20)
- NestJS come framework applicativo
- AWS DynamoDB come layer di caching con TTL
- Aurora Serverless v2 (PostgreSQL) come storage principale
- AWS X-Ray e CloudWatch Insights per il monitoraggio
- GitHub Actions + CDK per la pipeline di deploy
Conclusione
Aggiungere un sistema di caching non è stato un semplice miglioramento tecnico:
è stata una trasformazione architetturale che ha reso sostenibile l’intero ecosistema serverless.
In Shellonback, crediamo che l’innovazione non consista solo nel “cosa usi”, ma in come metti in relazione le tecnologie tra loro.
E questo progetto lo dimostra perfettamente.